
Klepsydra SDK Performance Benchmark on Odroid XU4
June 7, 2020
Klepsydra SDK Performance Benchmark on Odroid XU4 responds to a growing need for edge devices, specially in the robotics / IoT / UAV sector, that process large volumes of data on the edge, and not in the cloud. The reasons are mainly cost and the need to respond in real-time to data events.
Current software solution for edge data processing are less than able to cope with the requirements of the application and end up falling into data losses, long latency and overall unreliability of the software.
In this report, we present a high performance data processing solution that can speed up data processing substantially, while at the same time reduce CPU usage (i.e., energy consumption). All with out cloud or hardware updates.
Overview of the Klepsydra SDK Performance Benchmark on Odroid XU4
This technical report contains the results of the benchmark performed for the computer Odroid XU4. This benchmark consisted in testing increasing on-board data processing scenarios for different approaches to parallelism with and without ROS involved.
The results show that Klepsydra outperform in more than 50% traditional parallel data processing techniques.
Benchmarking Framework
The benchmark application consists of serialising to JSON matrices of 500×100 double. This matrix is built out of 100 double vectors arriving via the producer-consumer pattern. Consumers are constantly listening to messages that are filling up the next matrix to be serialised. The matrix population and the serialisation process occur sequentially in the same single thread.
The software is written in C++11 and has the following configuration parameters:
- Thread count. Number of producer threads.
- Publishing frequency. How many messages are sent per second.
Parallel data processing approaches.
Four different approaches were benchmarked for this report:
Single thread-safe queue. In this case a single queue is filled by all publishers in a concurrent manner. One consumer is in the receiving end filling the matrix for serialisation.
Multiple thread-safe queues. As opposed to the previous approach, in this case each publisher fills it owns associated queue, and has an associated consumer. Each consumer will race for access for the matrix and serialisation service.
Event Loop. Klepsydra’s main data processing approach. In this case publishers fill concurrently the event loop memory, while a single consumer receives all the data and fill the matrix safely.
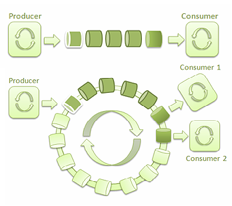
Figure 1. Thread safe queue and event loop diagrams.
Some of these approaches need the access to the matrix to be thread-safe and some of other don’t, the following table summarises this:
ROS Benchmark
| Thread-safe required | |
|---|---|
| Single safe queue | NO |
| Multiple safe queue | YES |
| Event Loop | NO |
Table 1. Approaches to data processing needing thread safe code.
The above mentioned approaches were run on memory only, and also in ROS two different approaches to data delivery:
- ROS spinOnce method. Which is a single thread mechanism offered by ROS Core C++ API
- ROS async method. In which a configurable number of threads are listening to ROS topics to receive the messaging data.
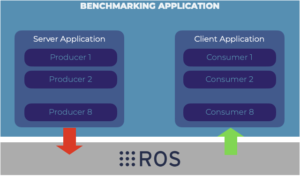
Figure 2. ROS publish subscribe setup for the performance benchmark.
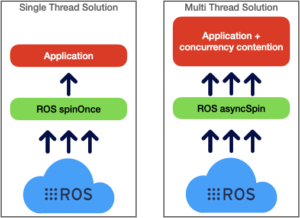
Figure 3. ROS two main approaches to data delivering to ROS subscribers.
The benchmark criteria
Three criteria are used to mesure the performance of the tested data processing approaches:
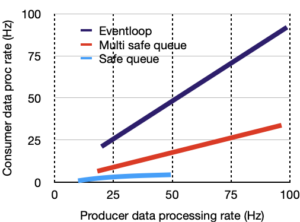
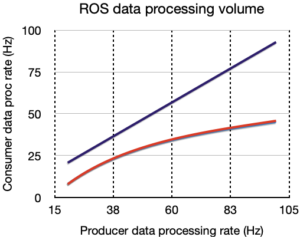
- Volume of data processing. Measured in two ways: number of producer threads and publication rate in Hz.
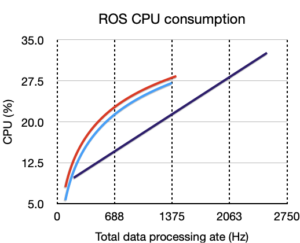
- CPU consumption. This is measured against data processing rate. I.e., how much CPU is required given a certain processed data volume.
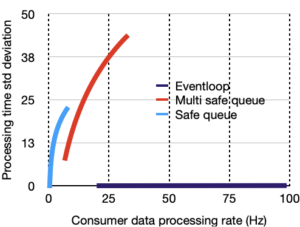
- Determinism. Measured as standard deviation of processing time required to process each data instance.
Technical specification of the benchmark
The test was run on the Odroid XU4 computer, with Ubuntu 18.04 and ROS melodic running natively.
The tests performed where under the following configuration settings:
| PARAMETER | Min | Max |
|---|---|---|
| Thread count | 10 | 40 |
| Publishing Rate | 20Hz | 100Hz |
| Pool size | 0 | 1024 |
Table 2. Benchmark configuration parameters
Performance results
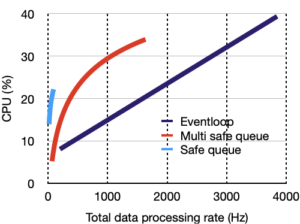
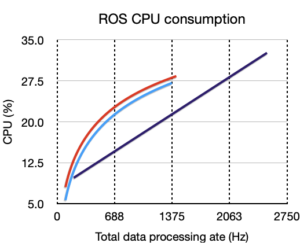
The performance results are shown in the last page of this report. They show that for the three evaluated criteria, Klepsydra SDK outperforms all the other approaches. The following table summarises this:
| Klepsydra | |
|---|---|
| Data processing | 100% increase |
| CPU usage | 25-50% reduction |
| Determinism | STD dev ~= 0 |
Table 3. Benchmarking results summary
Performance results
Left hand charts are for memory only benchmark, right hand, is for ROS.
Legend is:
Klepsydra, Multi-safe queue, Single safe queue
 |
 |
 |
 |
 |
 |
Download our community trial
Would you like to try Klepsydra Community? Thank you for your interest in the Klepsydra products. You can use the form below to access the link to our community edition
Request our professional trial
We offer a 90 days trial license including email support. Phone and onsite support and training can be requested.
Please fill the form below and our team will be in contact to provide access to download our products.